핸즈온 머신러닝
코딩관련깃허브
안녕하세요. 팀 언플(Team Unsolved Problem)에 에디터 ㅋ헬 킴(Khel Kim), 김현호입니다.
오늘은 지난 시간 Section 1. Look at the big picture에 이어서 Section 2. Get the data에 들어가겠습니다.
[Hands-on ML] Chapter 2. End-to-End Machine Learning Project1
그럼, 시작하겠습니다!
이 색션에서는 파이썬을 다운로드하고 디렉토리를 설정하고 필요한 모듈들을 다운받는데, 이러한 부분은 이 포스팅 취지에 맞지 않아 생략하겠습니다!
저도 나중에 안 사실인데, pip으로 모듈을 다운받아 사용하는 것보다 아나콘다를 사용하는 것이 더 빠르다고 합니다! ㅎㅎ
드디어 코드를 작성해 보겠습니다.
저희는 웹브라우저를 통해 housing.csv 데이터를 다운로드 할 수 있습니다. 하지만 보통 다운로드 해주는 함수를 만드는 것을 더 선호합니다. 왜냐하면 데이터가 정기적으로 업데이트된다면 조금의 수정으로 최신 데이터를 얻을 수 있기 때문입니다.
코드를 좀 보실까요(저희의 에디터는 쥬피터 노트북입니다).
import os
import tarfile
from six.moves import urllib
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml/master/"
HOUSING_PATH = "datasets/housing"
HOUSING_URL = DOWNLOAD_ROOT + HOUSING_PATH + "/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
fetch_housing_data()
일단 데이터를 불러오는 코드입니다. 저희 팀은 이 코드들을 처음 봤을 때 두려움에 떨었는데 혹시 저희와 같은 수준으로 시작하신 분들이 있을까 저희가 정리해놓은 것들을 써보겠습니다.
os 모듈을 부릅니다(path와 관련된 여려가지 일을 합니다).
tarfile 모듈을 부릅니다(압축된 파일을 열 수 있습니다).
urllib 모듈을 부릅니다(아마, 인터넷에 있는 자료를 받기 위해인 듯 합니다).
DOWNLOAD_ROOT 변수에 사이트 웹 주소를 저장합니다.
HOUSING_PATH 변수에 데이터가 있는 폴더 주소를 저장합니다.
HOUSING_URL 변수에 .tgz파일을 저장합니다.
지금부터 fetch_housing_data 함수를 정의하도록 하겠습니다. fetch_housing_data 함수에 들어가는 변수들은 데이터가 있는 웹주소, 그 데이터를 저장할 폴더입니다.
만약 housing_path가 존재하는 디렉토리가 아니면:
housing_path 디렉토리를 만듭니다.
tgz_path 변수에 housing_path\\housing.tgz를 저장합니다.
## 굳이 \\를 쓰면 될 것을 굳이 os.path.join함수를 쓰는 이유는
## 윈도우, 맥, 리눅스에 따라 파일 주소를 쓰는 방식이 다르기 때문입니다.
## os.path.join을 쓰게 되면 각 os에 맞게 주소를 연결해 줍니다.
웹사이트 housing_url을 타고 가서 파일을 다운로드 하고
datasets/housing이라는 디렉토리에 housing.tgz라는 파일을 만듭니다.
tgz_path에 있는 tgz파일을 엽니다.
housing_path 폴더에 tarfile을 추출합니다.
tgz 파일을 닫습니다.
fetch_housing_data 함수를 실행합니다.
## 함수를 실행하면, datasets/housing 폴더에 housing.tgz 파일이 다운 받아지고,
## housing 폴더에 tgz파일의 압축을 풉니다.
이제 데이터를 쥬피터 노트북 안에 불러오겠습니다.
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
housing = load_housing_data()
housing.head()
이 코드들을 해석해보면
pandas 모듈을 부릅니다(csv를 읽을 수 있는 모듈입니다).
load_housing_data 함수를 정의합니다.
csv_path 변수에 housing.csv 파일의 위치를 저장합니다.
함수의 결과값으로 pandas 모듈을 이용해 csv 파일을 데이터프레임 형태로 뱉습니다.
housing 변수에 housing.csv에 내용을 데이터프레임으로 저장합니다.
housing 데이터프레임에 맨 위 5 객체의 내용을 확인합니다.
이제 데이터를 간략하게 살펴봅시다.
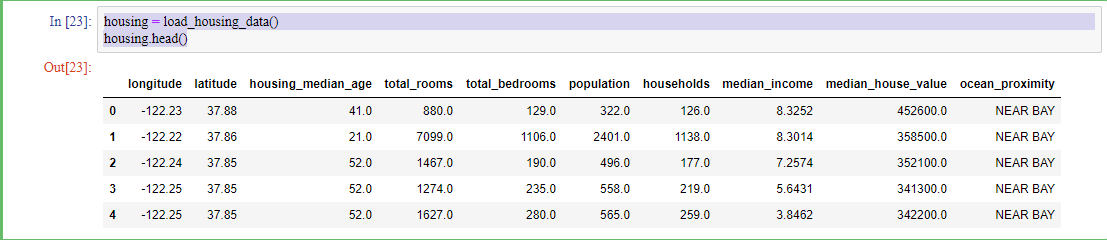
여기서 확인해야 할 것은 이 데이터가 어떤 특성들을 가졌는지 입니다.
이 데이터는 longitude, latitude, housing_meadian_age, total_rooms, total_bedrooms, population, households, median_income, median_house_vale, 그리고 ocean_proximity라는 특성을 가지고 있습니다.
머신러닝을 할 때 데이터를 바라볼 때 중요하게 여겨지는 부분 중 하나는 주어진 데이터의 특성이 명목형 변수인지 연속형 변수인지를 확인하는 것입니다.
이럴 떄 쓰기 좋은 함수가 데이터프레임의 info() 메소드입니다. 이 함수를 통해 결측치의 개수도 파악할 수 있습니다.
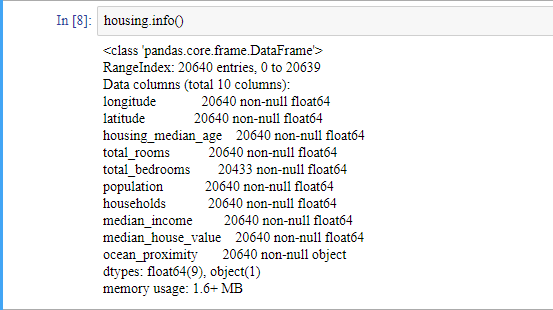
참고로 20,640 객체 수는 꽤 적은 수의 데이터량입니다.
데이터를 살펴보니 ocean_proximity는 object type입니다. 명목형 변수라는 것을 알 수 있습니다. 또, total_bed_rooms의 데이터는 20,433개로 결측치가 있다는 것을 알 수 있습니다. 이 결측치는 나중에 전처리 할 때 채워 넣도록 하겠습니다.
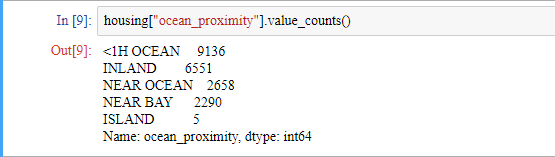
명목형 변수가 어떻게 구성되어 있는 지 확인해봅시다.value_counts() 메서드로 확인할 수 있습니다.
연속형 변수는 어떻게 구성되어 있는 지 확인해봅시다. describe() 메서드로 확인할 수 있습니다.
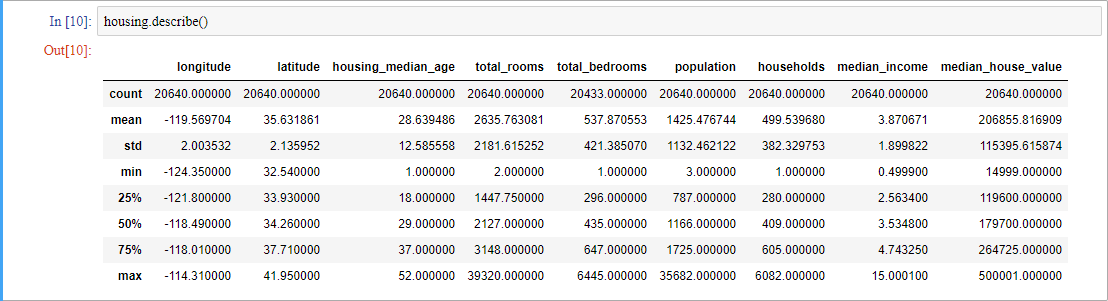
통계적 수치들이 나왔군요. 이 수치들은 결측치를 무시하고 낸 결과들입니다(자동으로 무시해줍니다).
이렇게 숫자가 많이 있을 때는 그림으로 보는게 직관에 더 와닿을 때가 있습니다.
%matplotlib inline
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20,15))
plt.show()
코드해석 ㄱㄱ
앞으로 그림을 쥬피터 노트북 안에 그립니다.
## '%'는 에디터인 쥬피터의 명령을 사용할 때 쓰는 기호입니다.
## matplotlib inline은 쥬피터가 업데이트되면서 굳이 쓰지 않아도 쥬피터 안에
## 그림을 그려줍니다.
matplotlib 모듈을 불러옵니다(그림을 그릴 때 필요합니다).
데이터프레임의 hist함수를 이용해서 그림을 그립니다.
## 구간의 개수는 50개, 사이즈는 20, 15(단위 inch)입니다.
그림을 그립니다.
plt.show()를 굳이 쓰지 않아도 되지만 쓰지 않으면 output에 보기싫은 애들이 나옵니다.
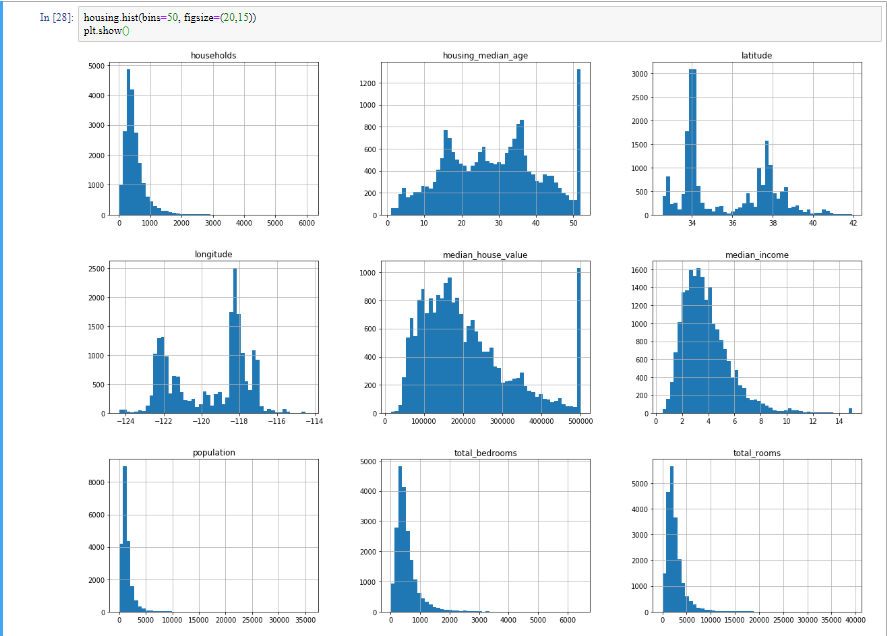
이 그림들을 바탕으로 체크해야 할 것들이 있습니다.
이제까지 저희는 데이터들을 간략하게 살펴보았습니다. 다음 포스팅에는 주어진 데이터를 train set과 test set을 나누는 작업을 살펴보겠습니다.