핸즈온 머신러닝
코딩관련깃허브
안녕하세요. 팀 언플(Team Unsolved Problem)에 에디터 ㅋ헬 킴(Khel Kim), 김현호입니다.
오늘은 지난 시간 Section 2.4 Create Test Set에 이어서 Section 3. Discover and visualize the data to gain insights에 들어가겠습니다.
[Hands-on ML] Chapter 2. End-to-End Machine Learning Project3
그럼, 시작하겠습니다!
지금까지는 다뤄야 할 데이터의 종류를 파악하기 위해서 데이터를 간단하게 살펴보았습니다. 이번 섹션에서는 저희의 데이터를 시각화 해보겠습니다. 지난 포스팅에서 말했던 이유로 당연히 테스트 세트를 떼어놓고 훈련 세트로만 가지고 시각화를 진행하겠습니다.
housing = strat_train_set.copy()
앞에서 했던 strat_train_set을 복사해서 housing 변수에 넣죠. 훈련 세트를 손상시키지 않게 얕은 복사를 통해 복사했습니다.
housing 데이터에는 지리 정보에 해당하는 위도와 경도가 있으니 모든 구역을 산점도로 만들어 데이터를 시각화해보겠습니다.
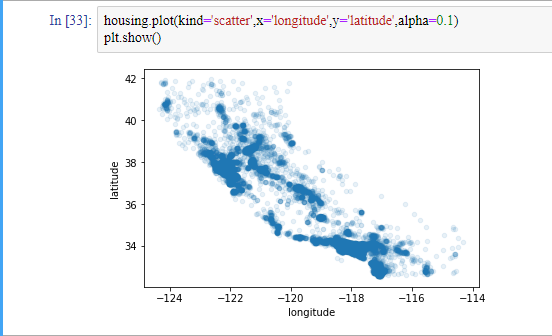
여기서, kind는 시각화의 종류를 나타내는 변수고, x는 x축에 들어갈 변수, y는 y축에 들어갈 변수입니다. alpha는 불투명 정도입니다. 더 자세한 정보는 여기에 있습니다. 이 시각화를 통해 우리는 데이터의 밀집정도를 알 수 있습니다.
매개변수들을 좀 더 다양하게 조작해서 두드러진 패턴을 체크해보겠습니다.
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing["population"]/100, label="population", figsize=(10,7),
c="median_house_value", colormap=plt.get_cmap('jet'), colorbar=True, sharex=False
)
plt.show()
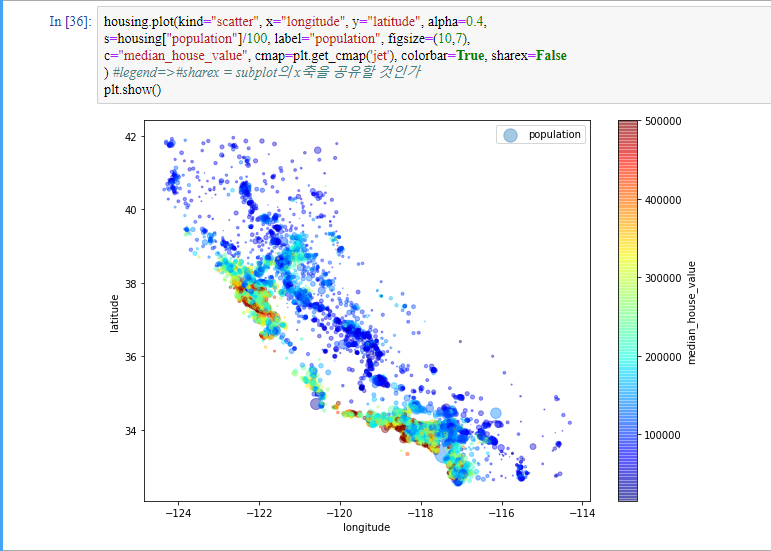
매개변수들을 먼저 해석해보겠습니다.
우리는 이 그림으로부터 집 값은 장소(예를 들면 바다와 가까운 곳) 그리고 인구 밀도와 관련이 있다는 것을 알 수 있습니다. 이런 내용은 군집 알고리즘(나중에 First with Tensorflow에서 알려드리겠습니다.)을 사용해 주요 군집을 찾고 군집의 중심까지의 거리를 재는 특성을 추가할 때 도움이 됩니다. 하지만 참고해야 할 것은 북부는 해안가라 하더라도 그다지 집값이 높지 않아 간단한 규칙이 적용되기는 어렵습니다.
데이터셋이 너무 크지 않다면 모든 특성 간의 표준 상관계수를 corr() 메소드를 사용해서 쉽게 계산할 수 있습니다.
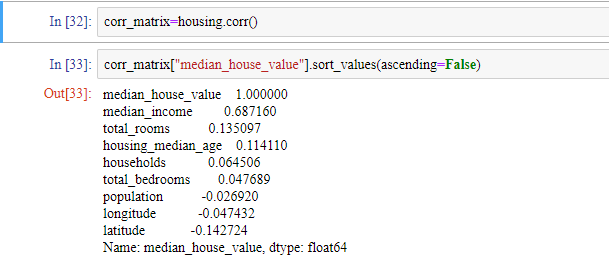
우리의 타겟인 median_hous_value와 다른 특성들의 상관관계를 조사해봅시다. 상관관계의 범위는 -1부터 1까지입니다. 상관관계가 -1에 가깝다면 강한 음의 상관관계를 나타내고 상관관계가 1에 가깝다면 강한 양의 상관관계를 나타냅니다. 상관관계가 0에 가깝다면 선형적 상관관계가 없다는 것입니다.
특성 사이의 상관관계를 확인하는 다른 방법은 숫자형 특성 사이에 산좀도를 그려주는 판다스의 scatter_matrix 함수를 사용하는 것입니다. 여기서는 숫자형 특성이 11개이므로 총 11^2 = 121개의 그래프가 되어 한 페이지에 모두 나타낼 수 없으므로, 중간 주택 가격과 상관관계가 높아 보이는 특성 몇 개만 살펴보겠습니다.
from pandas.plotting import scatter_matrix
attributes =["median_house_value",
"median_income","total_rooms","housing_median_age"]
scatter_matrix(housing[attributes],figsize=(12,8))
plt.show()
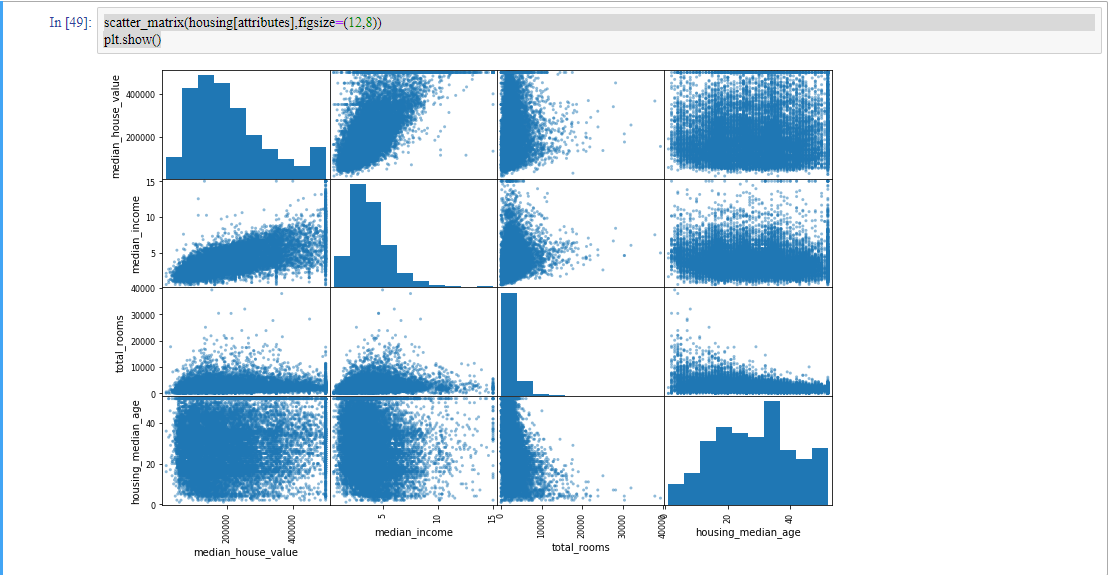
이 중에서는 집 값을 예측하는 데 가장 유용할 것 같은 특성은 median_income인 것 같군요. 이 상관관계 산점도를 확대해보겠습니다.
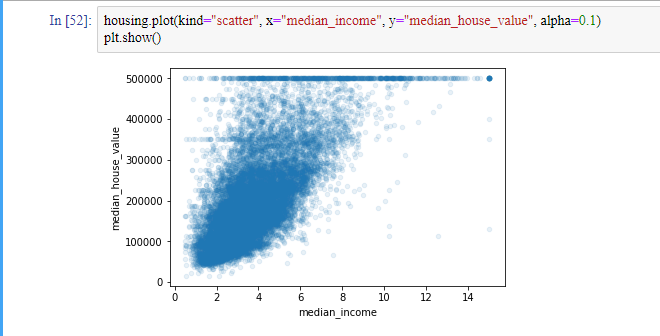
이 그래프는 몇 가지 사실을 보여줍니다.
가끔은 우리에게 주어진 특성 외에도 다른 특성들을 창출해내야할 때가 있습니다. 기존에 가진 특성들을 조합한다면 우리의 타겟 값에 더 큰 영향력을 가진 특성을 만들어 낼 수 있기 때문입니다. 이 데이터에서 조합할 수 있을만한 특성들을 확인해봅시다.
이러한 특성들을 조합해봅시다.
housing["rooms_per_household"] = housing["total_rooms"]/housing["households"]
housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]
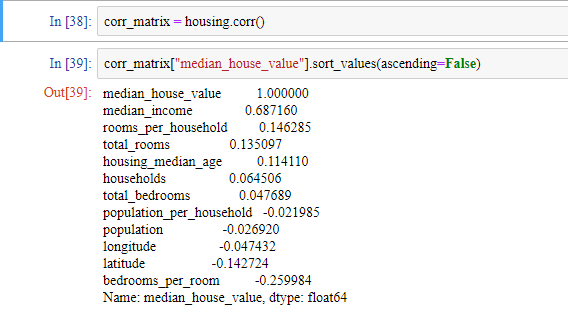
새로운 특성 중 bedrooms_per_room이나 rooms_per_household는 기존 특성들보다 더 유용한 것 같습니다.
시작을 잘해서 빨리 통찰을 얻는 것이 처음 프로토타입을 잘 만드는 데 도움이 될 것입니다. 하지만 이 과정은 반복적인 과정입니다. 우리의 알고리즘의 결과를 토대로 이 과정으로 돌아와서 데이터를 만족스러운 수준까지 업데이트 해야합니다.
지금까지 데이터를 시각화하는 방법과 특성 조합하는 방법을 배웠습니다. 다음 포스팅에는 데이터를 전처리 하는 작업을 살펴보겠습니다.