핸즈온 머신러닝
코딩관련깃허브
Author : Duck Hyeun, Ryu
안녕하세요. 팀 언플(Team Unsolved Problem)에 에디터 ㅋ헬 킴(Khel Kim), 김현호입니다. 오늘은 저희 팀에 오리, Duck Hyeun Ryu의 글을 정리 해서 업데이트하겠습니다.
오늘은 지난 시간 Section 3. Discover and visualize the data to gain insights에 이어서 Section 4. Prepare the data for Machine Learning algorithms에 들어가겠습니다.
[Hands-on ML] Chapter 2. End-to-End Machine Learning Project4
그럼, 시작하겠습니다!
이제 머신러닝 알고리즘을 위해 데이터를 전처리해보겠습니다. 이 단계는 최대한 자동화해야 하는데 이유를 설명해 드리겠습니다.
하지만 먼저 housing을 원래 훈련 세트로 복원하고, 예측 변수와 타깃 값에 같에 같은 변형을 적용하지 않기 위해 예측 변수와 레이블을 분리합시다.
housing = strat_train_set.drop("median_house_value", axis=1)
housing_labels = strat_train_set['median_house_value'].copy()
코드를 한번 읽어보겠습니다.
housing에 median_hous_value(타깃 값)을 뺀 복사본(얕은 복사)을 넣습니다. axis=1은 column방향으로 데이터를 삭제하겠다는 뜻입니다.
housing_labels에 median_income(타깃 값)을 얕은 복사로 넣습니다.
대부분의 머신러닝 알고리즘은 누락된 특성을 다루지 못합니다. 따라서 누락값들을 처리할 수 있는 함수를 만들겠습니다. 누락값들을 처리할 수 있는 방법은 3가지가 있습니다.
데이터프레임의 dropna(), drop(), fillna() 메서드를 이용해 이런 작업을 간단하게 처리할 수 있습니다. total_bedrooms 특성에 누락값이 있었으니 이를 처리해보죠!
housing.dropna(subset=["total_bedrooms"]) # option 1
total_bedrooms 특성 중 누락값인 객체를 제거합니다. axis=0이 default고 axis=1이면 열을 제거합니다.
housing.drop("total_bedrooms", axis=1) # option 2
total_bedrooms 특성 전체를 제거합니다. axis=1이면 열이 제거되고, axis=0이면 행이 제거됩니다.
median = housing["total_bedrooms"].median()
housing["total_bedrooms"].fillna(median) # option 3
median 변수에 total_bedrooms의 중위값을 넣습니다. 그리고 total_bedrooms의 누락값에 median을 채워넣습니다.
주의할 점은 나중에 테스트할 때, 테스트 세트의 누락값에 이 median값을 넣어줘야하기때문에 꼭 한 변수에 저장해야합니다.
사이킷런의 SimpleImputer라는 모듈은 이런 누락된 값을 처리할 수 있게 해주는 모듈입니다.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
housing_num = housing.drop("ocean_proximity", axis=1)
imputer.fit(housing_num) ##fit 메서드를 사용하면, imputer객체 변수에 housing_num의 특징을 넣음
imputer 변수에 strategy가 median인 SimpleImputer의 객체로 선언합니다. 그리고 housing_num 변수에 housing 데이터에 수치형 자료들을 저장합니다. (참고로 strategy는 mean, median, most_frequent, constant가 있습니다.)
imputer의 fit() 메서드를 이용하면 imputer객체 변수에 housing_num의 통계적 자료들을 저장합니다.

이제 학습된 imputer 객체를 사용해 훈련 세트에서 누락된 값을 학습한 중간값으로 바꿀 수 있습니다. 하지만 결과는 변형된 특성들이 들어 있는 평범한 넘파이 배열입니다. 따라서 판다스 데이터프레임으로 되돌려야 합니다.
X = imputer.transform(housing_num)
## 한 특성에는 중위값을 넣고, 한 특성에는 평균을 넣고 싶으면?? 분할 해야 하나???
## 넵 분할하면 됩니다.
housing_tr = pd.DataFrame(X, columns=housing_num.columns,
index=housing.index)
## housing_num.columns의 타입은 인덱스, housing.index의 타입은 인덱스,
## housing.index.values의 타입은 배열, list(housing.index.values)의 타입은 리스트
## index는 housing.index.value 혹은 list(housing.index.values)로 작성해도 됩니다.
## 책에서는 list(housing.index.values)입니다.
대부분의 머신러닝 알고리즘은 텍스트형 데이터를 다루지 못하므로 ocean_proximity를 숫자로 바꾸도록 해야합니다. 이를 위해 각 카테고리를 다른 정숫값으로 매핑해주는 판다스의 factorize() 메서드를 사용합니다.
housing_cat = housing["ocean_proximity"]
housing_cat_encoded, housing_categories = housing_cat.factorize()
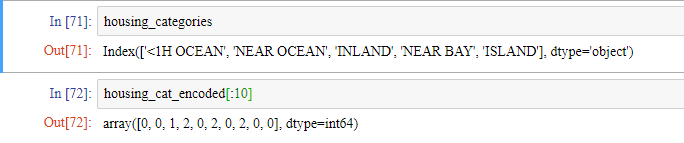
사이킷런의 OridinalEncoder 모듈을 이용해 같은 작업을 할 수 있습니다.
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = OrdinalEncoder(categories='auto') ## 자동으로 범주를 정해줍니다.
housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat.values.reshape(-1,1)) ## OrdinalEncoder은 2차원 배열을 받기 때문에 housing_cat을 2차원으로 바꿔줘야합니다.
## 하지만 데이터프레임에는 reshape 메서드가 없으므로
## 데이터프레임의 values를 가지고 numpy 배열을 만들고 reshape해줘야합니다.
housing_cat_encoded[:10]
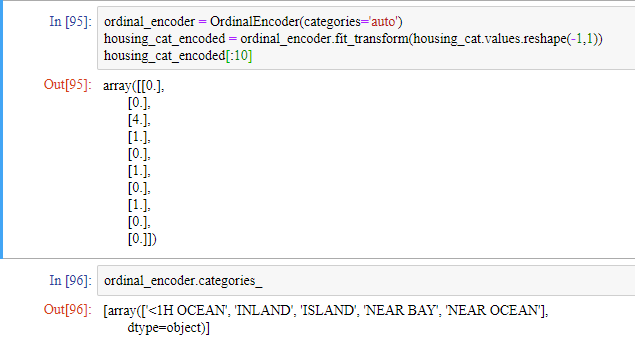
이런 표현 방식에는 문제가 있습니다. 실제로는 카테고리 0과 카테고리 1보다 카테고리 0과 카테고리 4가 의미적으로 더 비슷하지만, 위에 표현 방식으로는 알고리즘이 반대로 생각하기 때문입니다. 따라서 이를 해결하기 위해 원-핫 인코딩(one-hot encoding)을 해야합니다.
원-핫 인코딩이란 <1H OCEAN = [1, 0, 0, 0, 0]으로 표현하고 NEAR OCEAN=[0, 1, 0, 0, 0]으로 표현하는 것입니다. 단순 넘버링하는 것이 아니라 2차원 배열을 이용해 카테고리를 표현하는 것입니다. 그리고 각각의 배열을 원-핫 벡터라고 합니다.
사이킷런은 범주형 특성을 원-핫 벡터로 바꿔주는 OneHotEncoder를 제공합니다. OrdinalEncoder와 같은 이유로 housing_cat.values.reshape(-1,1)를 사용합니다.
from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder(categories='auto') ## 자동으로 범주를 정해줍니다.
housing_cat_reshaped = housing_cat.values.reshape(-1, 1)
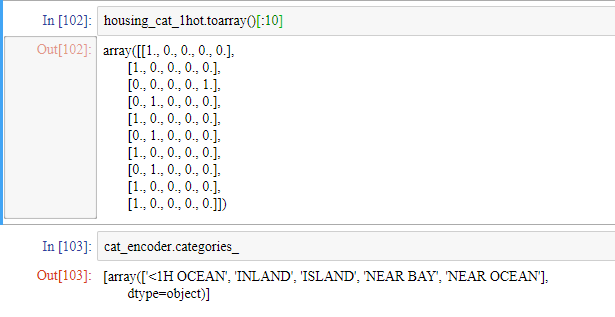
housing_cat_1hot = cat_encoder.fit_transform(housing_cat_reshaped)
housing_cat_1hot
원-핫 벡터는 0이 무수히 많으므로 있는 그대로 저장하면 메모리가 낭비됩니다. 따라서 0이 아닌 부분의 원소의 위치만 저장하는 희소행렬(sparse matrix)를 사용합니다.
sparse matrix를 우리가 아는 배열로 바꿀 때 사용하는 메서드는 toarray()입니다.
사이킷런에는 유용한 변환기가 있지만 특별한 정제 작업이나 어떤 특성들을 조합하는 등의 작업을 위해 자신만의 변환기를 만들어야 할 때가 있습니다. 이때는 내가 만든 변환기와 사이키런의 변환기와 매끄럽게 연동되어야 합니다. 그러기 위해서는 우리의 변환기에 fit()과 transform(), 그리고 fit_transform() 메서드들이 존재해야합니다(사이킷런의 변환기와 구조를 맞춰줘야 합니다).
앞서 만든 특성 조합을 추가하는 변환기를 작성해봅시다.
from sklearn.base import BaseEstimator, TransformerMixin
rooms_ix, bedrooms_ix, population_ix, household_ix = 3, 4, 5, 6
class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_per_room = True): # *args나 **kargs가 아니여야 합니다.
self.add_bedrooms_per_room = add_bedrooms_per_room
## add_bedrooms_per_room 특성을 추가할지 결정합니다.
## rooms_per_household 특성은 무조건 추가합니다.
## population_per_household 특성은 무조건 추가합니다.
def fit(self, X, y=None): #####덕 타이핑을 하기위해 넣어주는 요소
return self # fit() 메서드에서는 특별히 할 일이 없습니다.
def transform(self, X, y=None): ##### 실제로 transform을 하기 위한 요소
rooms_per_household = X[:, rooms_ix] / X[:, household_ix]
population_per_household = X[:, population_ix] / X[:, household_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix]
return np.c_[X, rooms_per_household, population_per_household, bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False) #### 3개의 combined된 attributes가 있는데 그 중 bedrooms per room을 제외함
housing_extra_attribs = attr_adder.transform(housing.values) ###housing.values 라는 배열에 추가로 2개의 attributes를 넣음
housing_extra_attribs = pd.DataFrame(
housing_extra_attribs,
columns=list(housing.columns)+["rooms_per_household", "population_per_household"]) ####array를 dataframe으로 만듦
많은 머신러닝 알고리즘은 입력 숫자 특성들의 스케일이 많이 다르면 잘 작동하지 않습니다. 예를 들면, 전체 방 개수의 범위 6~39.320, 중간 소득의 범위 0~15와 같이 특성의 스케일이 다르면 머신러닝 알고리즘이 잘 작동하지 않습니다. 따라서 스케일링 해주어야 합니다. 일반적으로 타깃 값은 스케일링이 불필요합니다.
사이킷런에는 변환을 순서대로 처리할 수 있도록 도와주는 Pipeline 클래스가 있습니다. 다음은 수치형 특성을 처리하는 파이프라인입니다.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
housing_num_tr = num_pipeline.fit_transform(housing_num)
Pipeline은 연속된 단계를 나타내는 (이름, 변환기) 쌍의 목록을 입력으로 받습니다. 각 단계에서는 fit_transform() 메서드를 가지고 있어야 합니다. 이름은 무엇이든 상관없지만, 이중 밑줄 문자(__)는 포함하지 않아야 합니다.
Pipeline안에서 실행되는 작업을 설명드리겠습니다. 파이프라인의 fit() 메서드를 호출하면 모든 변환기의 fit_transform() 메서드를 순서대로 호출하면서 한 단계의 출력을 바로 다음 단계의 입력으로 전달합니다. 마지막 단계에서는 fit() 메서드만 호출합니다.
파이프라인 객체는 마지막 추정기와 동일한 메서드를 제공합니다.
수치형 컬럼을 넘파이 배열로 추출하는 대신 판다스의 데이터프레임을 파이프라인에 직접 주입하면 좋을 것입니다.
from sklearn.compose import ColumnTransformer
num_attribs = list(housing_num) ## 참고, list(housing_num) 여기서 dataframe에 list를 하면 attributes가 나옵니다.
cat_attribs = ["ocean_proximity"]
full_pipeline = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", OneHotEncoder(categories='auto'), cat_attribs),
])
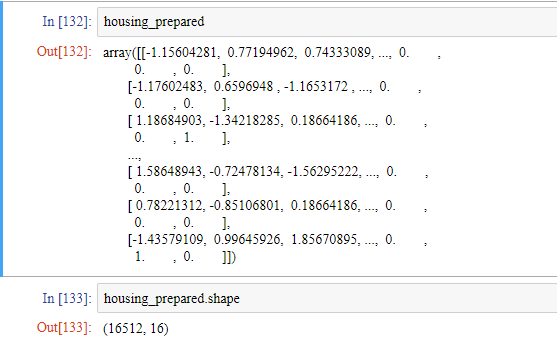
housing_prepared = full_pipeline.fit_transform(housing)
housing_prepared
사이킷런 0.20 버전 이전에는 ColumnTransformer 모듈이 없었습니다. 따라서 직접 변환기를 만들어야 했습니다.
class DataFrameSelector(BaseEstimator, TransformerMixin):
def __init__(self, attribute_names):
self.attribute_names = attribute_names
def fit(self, X, y=None):
return self
def transform(self, X):
return X[self.attribute_names].values ###배열로 나옴
이 DataFrameSelector를 이용하면
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
num_pipeline = Pipeline([
('selector', DataFrameSelector(num_attribs)),
('imputer', SimpleImputer(strategy='median')),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
cat_pipeline = Pipeline([
('selector', DataFrameSelector(cat_attribs)),
('cat_encoder', OneHotEncoder(sparse=False)),
])
이렇게 표현할 수 있습니다.
이 두 파이프라인을 하나의 파이프라인으로 연결할 수도 있습니다.
from sklearn.pipeline import FeatureUnion
full_pipeline = FeatureUnion(transformer_list=[
("num_pipeline", num_pipeline),
("cat_pipeline", cat_pipeline),
])
이 파이프라인을 실행해보겠습니다.
지금까지 데이터를 전처리하는 방법과 전처리를 해주는 변환기들을 연결하는 방법을 배웠습니다. 다음 포스팅에는 모델을 선택하는 작업과 훈련하는 작업을 살펴보겠습니다.