핸즈온 머신러닝
코딩관련깃허브
안녕하세요. 팀 언플(Team Unsolved Problem)에 에디터 ㅋ헬 킴(Khel Kim), 김현호입니다.
오늘은 지난 시간 Section 4. Prepare the data for Machine Learning algorithms에 이어서 Section 5. Select a model and train it에 들어가겠습니다.
[Hands-on ML] Chapter 2. End-to-End Machine Learning Project5
그럼, 시작하겠습니다!
지금까지 해온 것들을 정리하자면, 문제를 정의하고 데이터를 읽어 들이고 탐색했습니다. 그리고 데이터를 훈련 세트와 테스트 세트로 나누고 머신러닝 알고리즘에 주입할 데이터를 자동으로 정제하고 준비하기 위해 변환 파이프라인도 작성했습니다. 이제 머신러닝 모델을 선택하고 훈련시킬 준비가 되었습니다.
처음으로 저희가 사용할 모델은 선형 회귀 모델입니다(모델들은 나중에 자세히 다루겠습니다. 지금은 어떻게 사용하는 지만 익혀두죠).
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_labels)
이게 끝입니다. 사이킷런에서 LinearRegression 모델을 부르고, 주어진 데이터와 레이블을 lin_reg의 fit 메서드에 넣기만 하면 모델이 완성됩니다.
훈련 세트에 있는 몇 개 샘플에 적용해보겠습니다.
some_data = housing.iloc[:5]
some_labels = housing_labels.iloc[:5]
some_data_prepared = full_pipeline.transform(some_data)
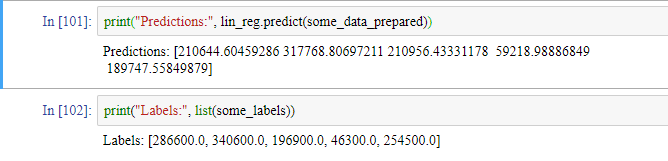
정확한 예측은 아니지만 작동은 합니다. 사이킷런의 mean_square_error 함수를 사용해서 전체 훈련 세트에 대한 이 회귀 모델의 RMSE를 측정해보겠습니다
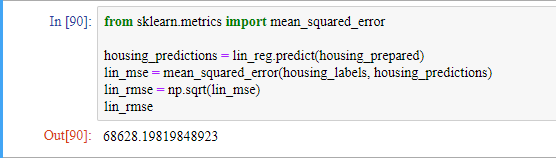
대부분 구역의 중간 주택 가격은 12000에서 265000 사이입니다. 그러므로 예측 오차가 68628인 것은 매우 만족스럽지 못한 결과입니다. 이러한 상황을 ‘모델이 훈련 데이터에 과소적합되었다’라고 말합니다. 이런 상황은 특성들이 좋은 예측을 만들만큼 충분한 정보를 제공하지 못했거나 모델이 충분히 강력하지 못하다는 사실을 말해줍니다.
과소적합을 해결하는 주요 방법은
등이 있습니다. 저희는 더 강력한 모델을 선택하는 것으로 이 문제를 해결해보죠.
다음으로 저희가 사용할 모델은 DecisionTreeRegressor를 훈련시켜보겠습니다. 이 모델은 강력하고 데이터에서 복잡한 비선형 관계를 찾을 수 있습니다.
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(random_state=42)
tree_reg.fit(housing_prepared, housing_labels)
모델을 훈련 시켰습니다. 훈련 세트로 성능을 평가하도록 하겠습니다.
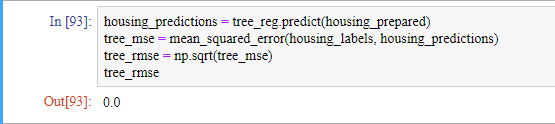
오차가 전혀 없습니다. 이는 모델이 훈련 데이터에 너무 과대적합된 것으로 보입니다. 하지만 과대적합되었다고 확신하기 위해서는 어떻게 해야할까요? 테스트 세트를 써야할까요? 우리는 확신이 드는 모델이 론칭할 준비가 되기 전까지는 테스트 세트를 사용하지 않아야 합니다. 따라서 이 상황에서는 훈련 세트의 일부분으로 훈련을 하고 다른 일부분은 모델 검증에 사용하는 방법을 써야합니다.
결정 트리 모델을 평가하기 위해 저희는 train_test_split 함수를 사용해 훈련 세트를 더 작은 훈련 세트와 검증 세트로 나누고, 더 작은 훈련 세트에서 모델을 훈련시키고 검증 세트로 모델을 평가하는 방법이 있습니다. 하지만 이 방법은 번거롭습니다.
사이킷런의 교차 검증 기능을 사용하면 이를 쉽게 할 수 있습니다. K-겹 교차 검증(K-fold cross-validation)이라고 불리는 방법입니다. 훈련 세트를 폴드(fold)라 불리는 10개의 서브셋으로 무작위로 분할합니다. 그런 다음 결정 트리 모델을 10번 훈련하고 평가하는데, 매번 다른 폴드를 선택해 평가에 사용하고 나머지 9개 폴드는 훈련에 사용합니다. 10개의 평가 점수가 담긴 배열이 결과가 됩니다.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
tree_rmse_scores = np.sqrt(-scores)
여기서 cv가 폴드의 개수입니다. 사이킷런의 교차 검증 기능은 scoring 매개변수에 (낮을수록 좋은) 비용 함수가 아니라 (클수록 좋은) 효용 함수를 기대합니다. 그래서 평균 제곱 오차(MSE)의 반댓값(즉, 음숫값)을 계산하는 neg_mean_squared_error 함수를 사용합니다. 그래서 마지막에 제곱근을 계산하기 전에 -scores로 부호를 바꿨습니다.
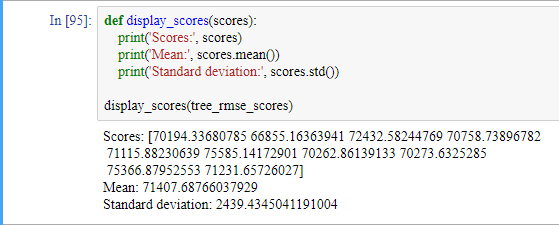
결과를 살펴보겠습니다
비교를 위해 선형 회귀 모델의 점수를 계산해보겠습니다.
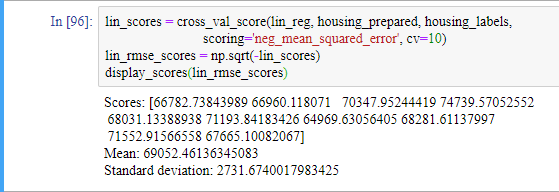
DecisionTreeRegressor 모델의 결과가 실제로는 선형 회귀 모델보다 결과가 좋지 않습니다. 교차 검증으로 모델의 성능을 추정하는 것뿐만 아니라 이 추정이 얼마나 정확한지를 표준편차로 측정할 수 있습니다.
DecisionTreeRegressor 모델이 과대적합되어 선형 회귀 모델보다 성능이 나쁩니다.
저희의 마지막 모델은 RandomForestRegressor 모델입니다.
from sklearn.ensemble import RandomForestRegressor
forest_reg = RandomForestRegressor(random_state=42)
forest_reg.fit(housing_prepared, housing_labels)
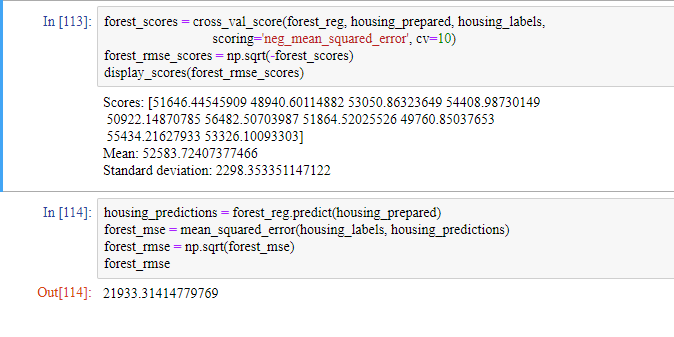
랜덤 포레스트는 매우 훌륭해 보입니다. 하지만 훈련 세트에 대한 RMSE가 검증 세트에 대한 RMSE보다 훨씬 낮으므로 이 모델도 여전히 훈련 세트에 과대적합되어 있습니다.
과대 적합을 해결하는 방법은
입니다.
그러나 랜덤 포레스트를 더 깊이 들어가기 전에, 여러 종류의 머신러닝 알고리즘으로 하이퍼파라미터 조정에 너무 많은 시간을 들이지 않으면서 다양한 모델을 시도해야합니다. 가능성 있는 2~5개 정도의 모델을 선정하는 것이 목적입니다.
가능성 있는 모델들을 추렸다고 가정하겠습니다. 이제 이 모델들을 세부 튜닝해보겠습니다.
만족할 만한 하이퍼파라미터 조합은 사이킷런의 GridSearchCV를 사용하면 구할 수 있습니다. 탐색하고자 하는 하이퍼 파라미터와 시도해볼 값을 지정하면 됩니다.
from sklearn.model_selection import GridSearchCV
param_grid = [
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},
]
forest_reg = RandomForestRegressor(random_state=42)
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error', return_train_score=True)
grid_search.fit(housing_prepared, housing_labels)
이 방법은 시간이 꽤 오래걸리지만 최적의 조합을 얻을 수 있습니다.

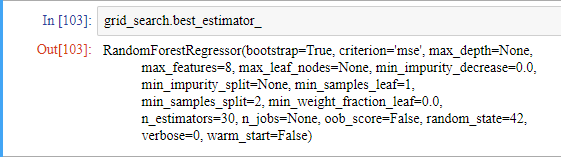
최적의 추정기에 직접 접근할 수도 있습니다.
평가 점수도 확인할 수 있습니다.
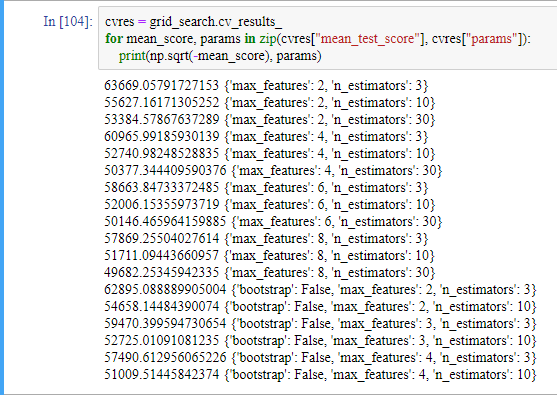
참고로 cvres는 딕셔너리 자료형입니다.
그리드 탐색 방법은 이전 예제와 같이 비교적 적은 수의 조합을 탐구할 때는 괜찮지만 하이퍼파라미터 탐색 공간이 커지면 RandomizedSearchCV를 사용하는 편이 좋습니다. RandomizedSearchCV는 각 반복마다 하이퍼파라미터에 임의의 수를 대입하여 지정한 횟수만큼 평가합니다. 랜덤 탐색의 장점은 두 가지입니다.
최상의 모델을 연결하는 것도 좋은 방법입니다. 이 주제는 7장에서 자세히 살펴보겠습니다.
최상의 모델을 분석하는 것도 좋은 방법입니다. 예로 RandomForestRegressor가 정확한 예측을 만들기 위한 각 특성의 상대적인 중요도를 살펴보겠습니다.
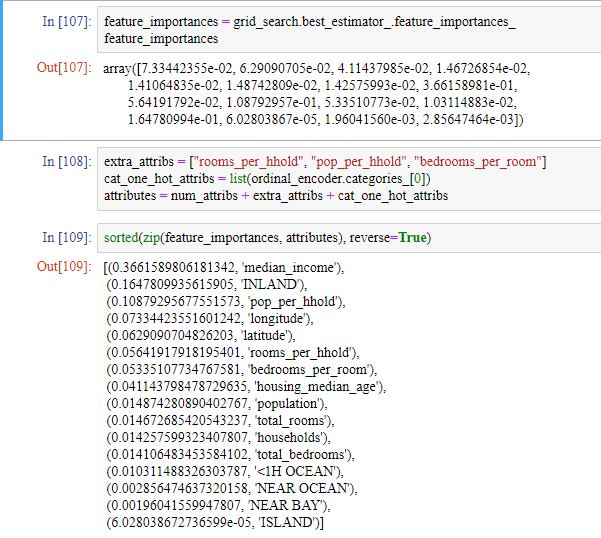
이 정보를 바탕으로
등을 시도할 수 있습니다.
이렇게 모델들을 튜닝하고 나면 드디어 테스트 세트에서 최종 모델을 평가할 때입니다.
final_model = grid_search.best_estimator_
X_test = strat_test_set.drop("median_house_value", axis=1)
y_test = strat_test_set["median_house_value"].copy()
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
여기서 주의해야할 부분은
X_test_prepared = full_pipeline.transform(X_test)
입니다. 만약 fit_transform 메서드를 사용하면 테스트 세트에 대한 정보가 파이프라인에 저장되게 됩니다. 따라서 transform 메서드를 사용해야 합니다.
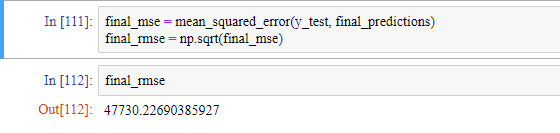
하이퍼파라미터 튜닝을 많이 했다면 교차 검증을 사용해 측정한 것보다 조금 성능이 낮은 것이 보통입니다. 혹시 많이 낮아지는 경우가 생기더라도 테스트 세트에서 성능 수치를 좋게 하기위해 하이퍼파라미터를 튜닝하려 하면 안됩니다. 왜냐하면 그렇게 향상된 성능은 새로운 데이터에 일반화되기 어렵습니다.
이제 학습한 것, 한 일과 하지 않은 일, 수립한 가정, 시스템 제한사항 등을 강조하면서 솔루션과 문서를 출시하고, 깔끔한 도표와 기억하기 쉬운 제목으로 발표 자료를 만들면 됩니다!!
지금까지 전반적인 데이터 분석과 머신 러닝 사용 방법을 배웠습니다. 이대로 2단원을 마치고 다음 포스팅에는 회귀 작업말고 분류작업을 어떻게 하는지 3단원을 살펴보겠습니다.