앞으로 우리팀에서 스터디를 통해 공부했던 내용들을 정리하여 각 주마다 연재를 할 계획입니다. 저희가 처음 머신러닝을 접해서 차례대로 공부한 내용들을 올리는 것이니 머신러닝을 처음 시작하시는 분들께서 보신다면 도움이 될것입니다.
그럼, 시작하겠습니다!
머신러닝을 시작하기 전에 ‘머신러닝’에 있는 ‘러닝’, 즉 데이터 사이언스의 분야에서 ‘학습’이란 무엇인지 정의해보겠습니다.
우리의 목표는 컴퓨터를 학습시키는 것입니다. 컴퓨터에게 당장 학습을 시켜야 한다면 어떤 방법이 좋을까요?
사람들은 컴퓨터를 어떻게 학습시킬지 생각하다가 사람의 학습방법을 모방하기로 합니다. 여기서는 미시적 수준 (즉, 세포 수준)에서 학습에 관여하는 각 세포들의 역할을 알아보겠습니다.
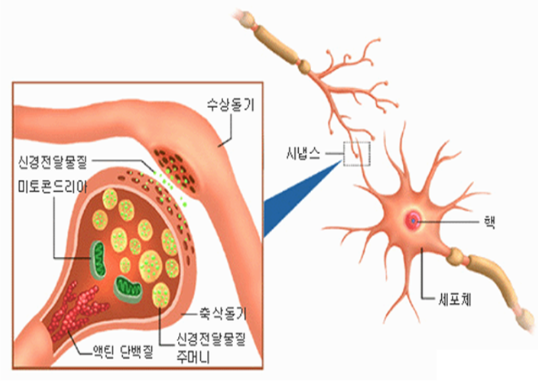
그림에서 틀린 부분을 한번 찾아볼까요?!

정답은 5개입니다
왜 갑자기 틀린그림찾기를 했을까요?
우리는 학습을 할 때 중요한 특징을 잡습니다. 즉, 어떠한 특징들에게 가중치를 두고 학습을 하는데 우리는 저 그림에서 ‘틀린그림찾기’의 목적에 맞춰서 두 그림의 다름에 가중치를 두고 판단을 내립니다. 그 결과로 정답을 도출해내는 것이죠. 우리는 이러한 메커니즘을 기계에게도 적용시키고자 합니다.
이것이 바로 Hebbian Rule입니다.
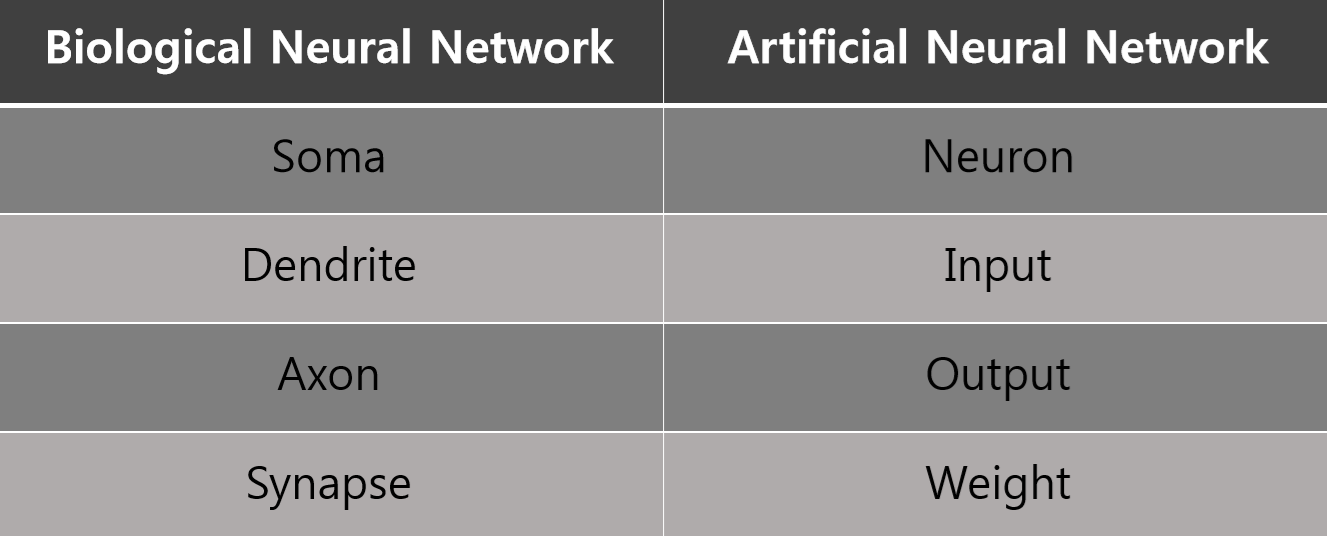
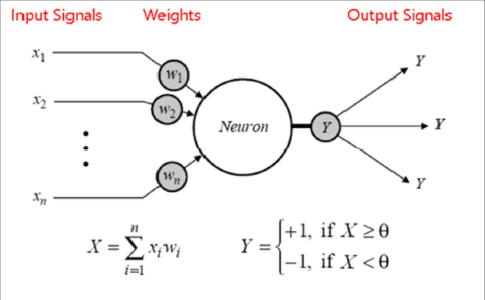
즉, 학습의 중요한 요소인 시냅스(가중치(weight))와 세포체(활성함수(activation function))의 개념을 갖는 인공뉴런을 만든다면, 학습이 가능해지는 것입니다!
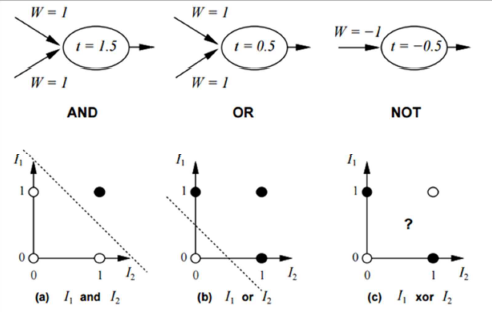
그림에서 처럼 XOR 문제는 선형적으로 구분하기 어렵습니다.
(하지만 single layer가 아니라 multi-layer를 이용하면 구현할 수 있습니다)
활성 함수에는 다양한 종류가 있습니다.
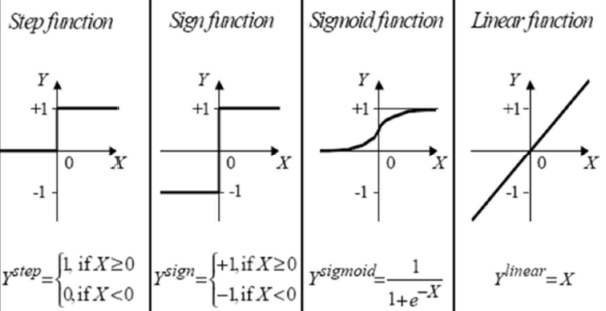
‘Sign Function’이나 ‘Step Function’은 단지 두개의 값만 가능하기 때문에 표현의 한계가 있습니다.
‘Linear Function’을 사용할지라도 비선형 조건을 표현할 수 없습니다.
여러 장점들 때문에 주로 ‘Sigmoid Function’이나 ‘Hyperbolic Tangent Function’과 같은 비선형 함수를 활성함수로 사용합니다.
하지만 ‘Sigmoid Function’을 사용한다 해도 망이 깊어지는 Deep Neural Network에서는 학습의 어려움으로 인해 ReLU(Rectifier Linear Unit)을 주로 사용합니다.
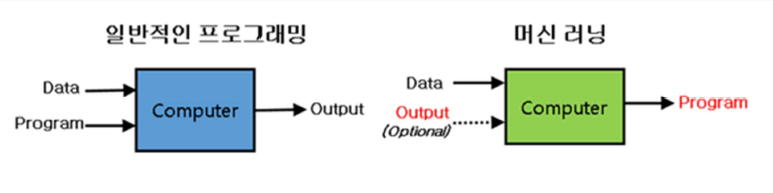
일반적인 프로그래밍은 데이터와 프로그램을 주면 함수를 도출해내지만, 머신러닝은 데이터와 결과값을 주면 프로그램을 도출합니다.
학습(Training)
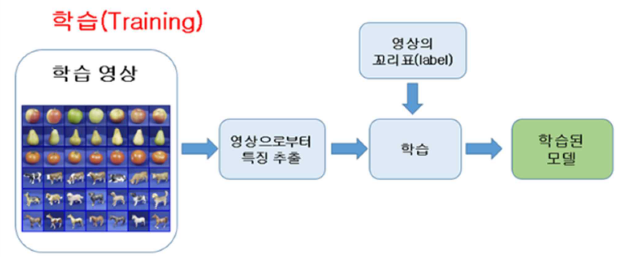
검사(Testing)
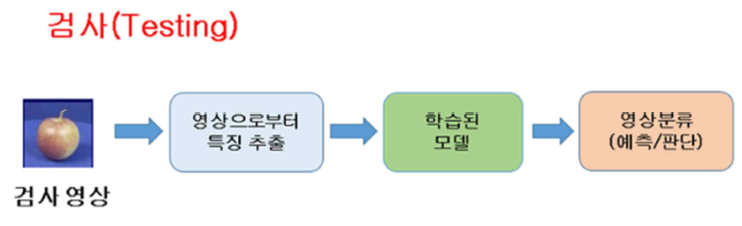
검증(Validation)
검증단계에선 학습과 다른 데이터를 이용해 학습이 제대로 되었는지를 확인합니다.
(너무 주어진 학습데이터에만 특화 되면, 학습 데이터에서 조금만 입력이 들어오더라도 결과가 나쁘게 나올 수 있습니다. 이를 ‘오버피팅(Overfitting)’ 혹은 ‘과적합’이라고 합니다.)
설계자의 역할은 좋은 알고리즘을 선별하여 사용하고 질 좋고 많은 학습 데이터를 모델에 주는 것입니다.
출처 : 쉽게 읽는 머신 러닝 - 라온피플