지난 포스트에는 머신러닝의 framework에 대해서 알아보았습니다.
[쉽게읽는 머신러닝-라온피플] 1. 머신러닝 framework
오늘은 머신러닝의 학습방법과 몇 가지 종류의 머신러닝 모델(Boosting and Bagging)에 대해서 알아보겠습니다!
그럼, 가 봅시다!!
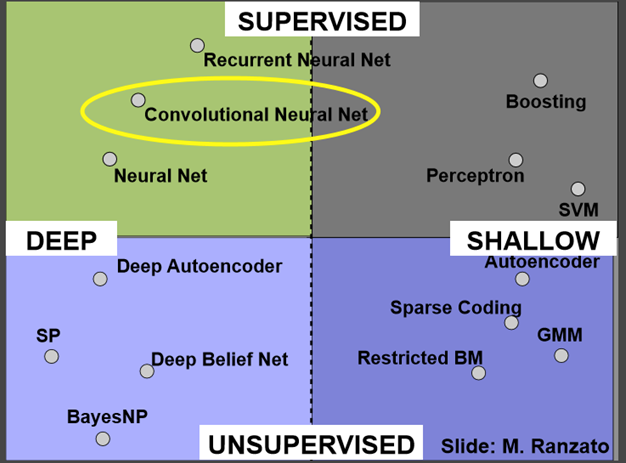
먼저, 머신 러닝 알고리즘의 종류는 매우 다양하고 여러 카테고리로 나뉩니다.
무작위로 선택하는 것보다 약간 가능성이 높은 규칙(weak learner)들을 결합시켜 보다 정확한 예측 모델을 만들어 내는 것입니다.
(Weak learner : 무작위로 선정하는 것보다는 성공 확률이 높은, 즉 오차율이 50% 이하인 학습 규칙)
매번 기본 러닝 알고리즘을 적용할 때 마다 새로운 Weak learner를 만들며, 이 과정을 반복적으로 수행합니다.
이 Weak learners를 하나로 모아서 Strong learner를 만듭니다.
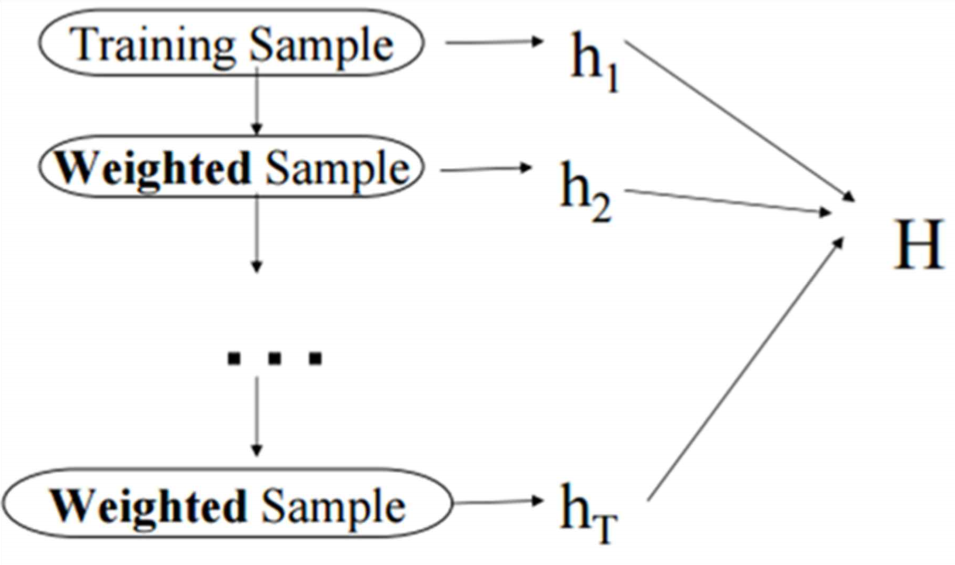
Weak learner를 이용해 학습을 하면서 에러가 발생하면, 그 에러에 좀 더 집중하기 위해 error에 대한 weight를 올리고, 그 에러를 잘 처리하는 방향으로 새로운 Weak learner를 학습시킵니다.
최종 결과는
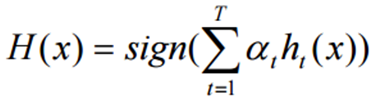
과 같이 표현되며, 여기서 αt는 가중치입니다.
Boosting은 새로운 Learner를 학습할 때마다 이전 결과를 참조하는 방식이며, 이것이 뒤에 나올 Bagging과 다른 점입니다.
최종적으로 Weak learner로부터의 출력을 결합하여 더 좋은 예측율을 갖는 Strong learner가 만들어 집니다.
먼저 표본을 취하고, 그 표본에 대한 분포를 구합니다. 그리고 나서 표본을 전체라고 생각하고, 표본으로부터 많은 횟수에 걸쳐(동일한 개수의) 샘플을 복원 추출(Resample with replacement)한 후 각 샘플에 대한 분포를 구합니다.
그 후 전체 표본의 분포와 샘플들 간의 분포의 관계를 통해, 전체 집단의 분포를 유추하는 방식입니다.
Regression의 경우는 평균(model averaging)을 취해 분산(variance)를 줄이는 효과를 얻을 수 있고, 분류(classification)에서는 투표 효과(voting)을 통해 가장 많은 결과가 나오는 것을 취하는 방식을 사용합니다.
Bagging의 예 -위키피디아
(Bagging과 Boosting에 대해서는 추후에 Hands-on Machine learning 책을 정리할 때 더 자세히 다루겠 습니다.)
출처 : 쉽게 읽는 머신 러닝 - 라온피플