지난 포스트에는 머신러닝의 학습 방법과 Bagging, 그리고 Boosting에 대해서 알아봤습니다.
[쉽게읽는 머신러닝-라온피플] 2. 머신러닝의 학습방법
오늘은 머신러닝의 모델 중 하나인 결정트리에 대해 알아보는 시간을 가지겠습니다!
그럼, 가 봅시다!!
시드니 대학의 J.Ross QuinLan이 한 모델을 만들었고 그것을 그의 책 ‘Machine Learning, Vol.1, No.1, in 1975’에 실었습니다.
그의 첫 Decision Tree 알고리즘은 Iterative Dichotomiser3 (ID3)이라고 부릅니다.
Decision Tree는 나무 모양의 그래플르 사용하여 최적의 결정을 할 수 있도록 돕는 방법(알고리즘)입니다.
이 알고리즘을 Machine Learning에 적용한 것을 Decision Tree Learning 혹은 그냥 Decision Tree라고 부릅니다.
기회비용에 대한 고려, 기대 이익 계산, 자원의 효율적 사용이나 위험관리 등 효율적 결정이 필요한 분야에 사용합니다.
어떤 항목에 대한 관측값(Observation)에 대하여 가지(Branch) 끝에 위치하는 기대 값(Target)과 연결시켜주는 예측 모델(Predictive Model)입니다.
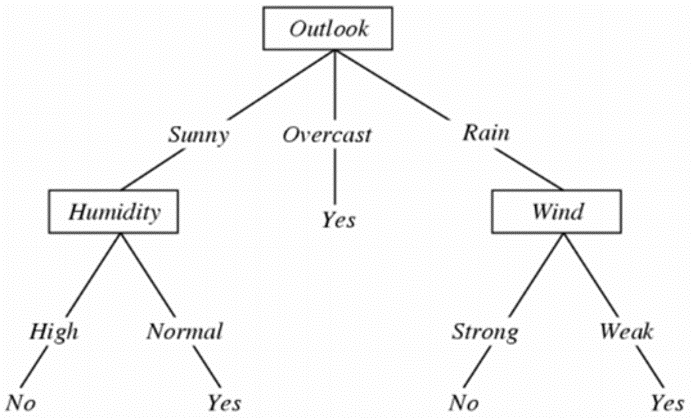
(예시에서) 습도, 날씨, 바람은 판단의 기준입니다.
목적에 따라 많은것이 올 수 있습니다.
속성엔 여러 값이 있을 수 있습니다.
Decision Tree의 다른 예제 :
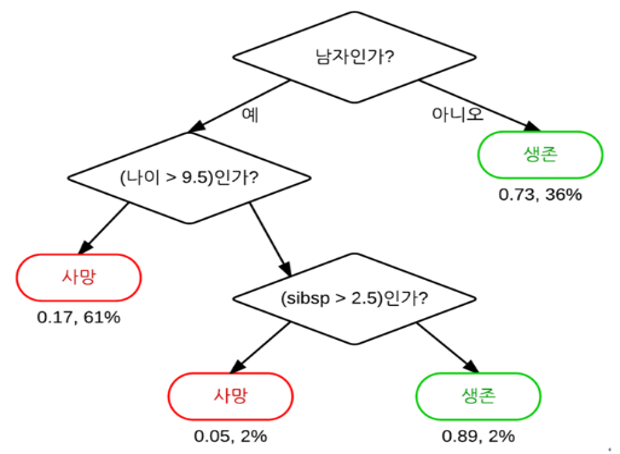
Decision Tree를 구성하는 방법은 여러가지 입니다. 속성이 여러 개 있는 경우 어떤 속성을 Root Node(최상단 노드)에 둘지 중요합니다. 일반적으로 더 Compact하게 만드는 것이 목적이고 이를 위해 ‘엔트로피‘를 이용합니다.
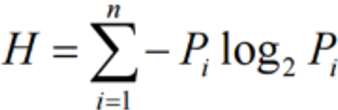
(Pi : 특정값 i가 일어날 확률)
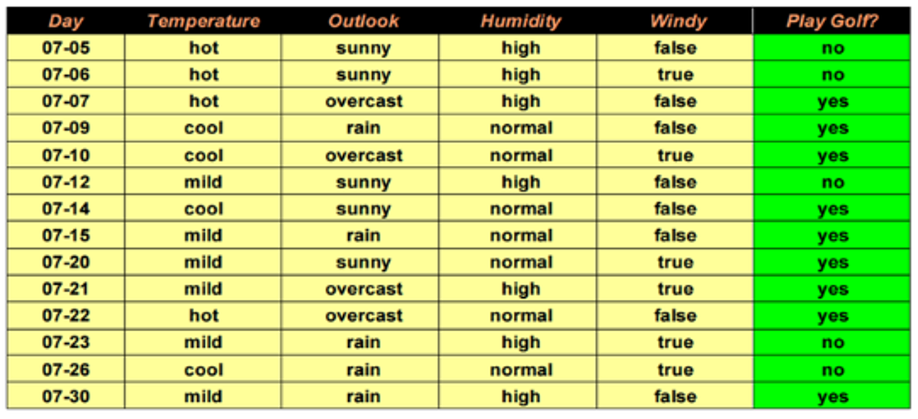
위의 표는 14일 동안 골프를 치거나 치지 않을 경우에 조건들을 담고 있습니다. Decision Tree를 이용하면 깔끔하게 정리할 수 있고 쉽게 예측할 수 있습니다.
먼저 우리가 판단해야 할 것은 골프를 칠것인가 안칠것인가 하는 것입니다. 예제의 4개의 속성은 Temperature, Outlook, Humidity, Windy입니다. 최적의 Decision Tree를 만들려면 각각의 속성에 대한 엔트로피를 계산해야 합니다.
계산 결과,
가 나옵니다.
즉, Outlook이 최고 높은 엔트로피를 가지므로 Outlook을 Root Node로 결정합니다. 그 후 Outlook 속성에 있는 3가지 값을 사용하여 같은 방식으로 다음 노드를 결정합니다.
결과적으로…
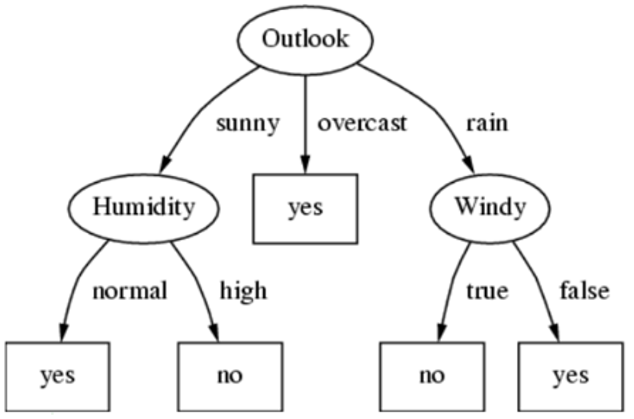
이런 모양의 Decision Tree가 완성이 됩니다!
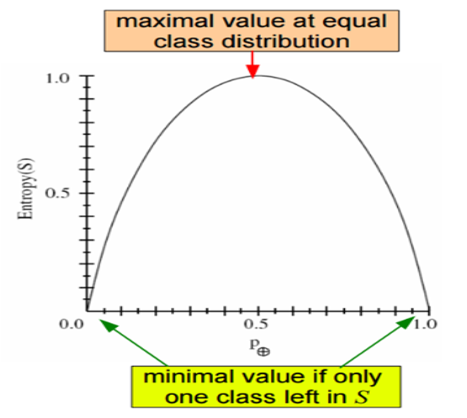
위 그림은 속성이 2개인 경우에 데이터의 분포에 따른 엔트로피의 변화를 보여주는 그림입니다.
분포가 고르면 큰 값을 가지고, 특정값으로 몰려 있으면 0에 가까워 집니다.
코딩에 필요한 bit효율(log2를 쓰는 Entorpy의 단위가 bit)이 올라간다는 것은 엔트로피가 올라간다는 것이고, 결과적으로 효율적인 Decision Tree가 만들어진다는 의미입니다.
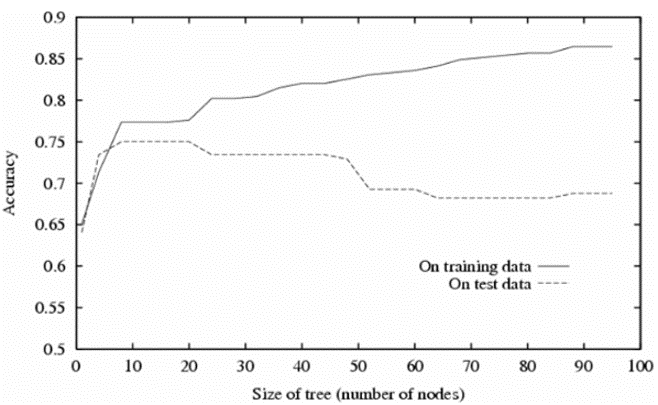
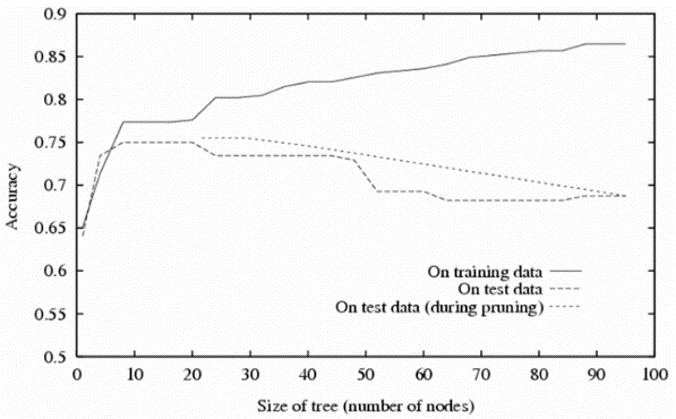
통상적으로 크기(노드의 개수)가 대략적으로 23 이상이 되면 Test에 대한 정확도가 점점 감소합니다.
트리가 커지면 세밀한 분류가 가능하지만, Overfitting될 가능성이 높아집니다.
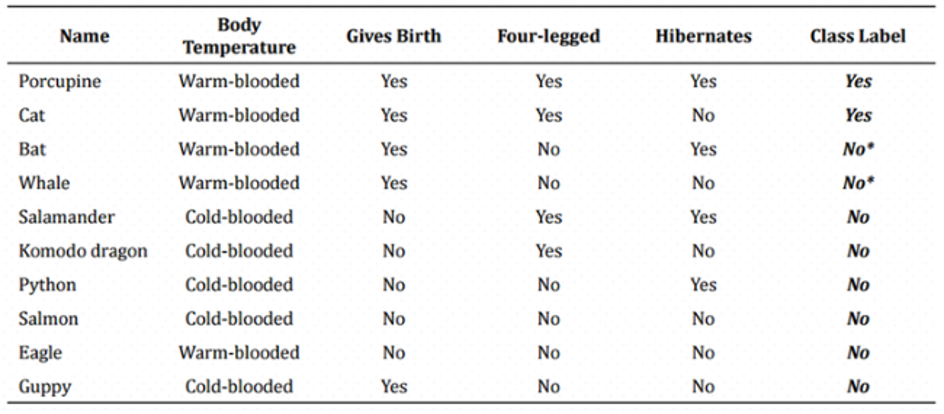
이 표를 통해서 포유류를 구분하는 모델을 만들생각입니다. 어랏! 그런데 표에 데이터 잡음으로 인해 Bat과 Whale에 엉뚱한 Label이 붙었습니다. 이것을 이용해 Decision Tree를 만들면…
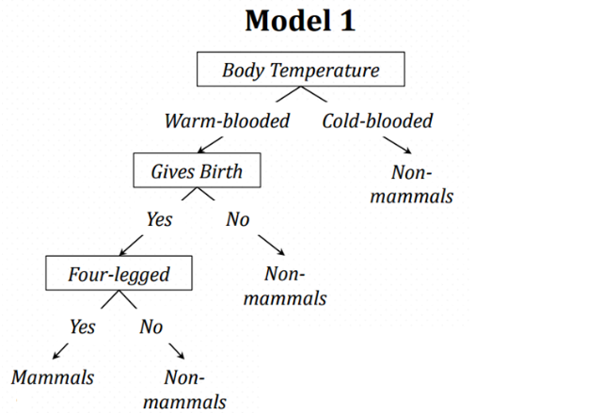
이 모델을 통해서 다음 주어진 테스트 데이터로 테스트를 하면…
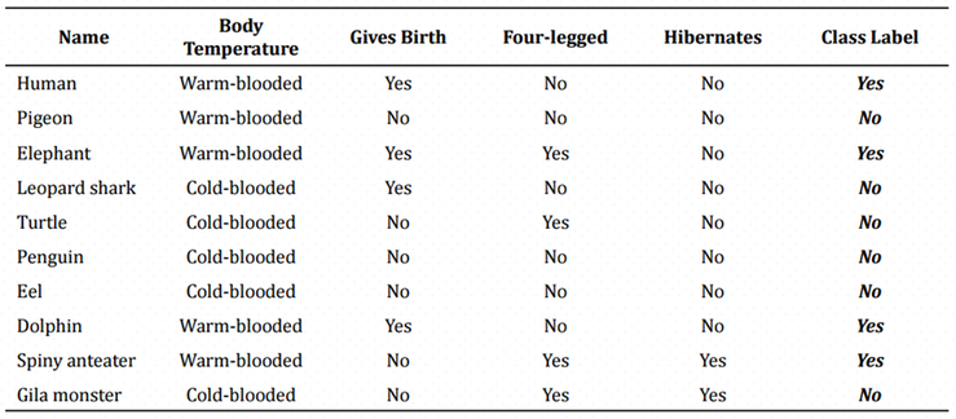
사람과 돌고래는 다리가 4개가 아니기 때문에 포유류가 아니라고 하는군요!
가지치기를 실행하면 학습데이터에 대한 Error가 발생합니다. 하지만 테스트 데이터에 대한 Error는 감소하죠.
학습 데이터를 통해 학습시킨 후 결과 검증을 위한 검증 데이터를 이용해 학습 결과의 특화 여부를 판단하고, 선 가지치기(Pre-Pruning)와 (후 가지치기)Post-Pruning을 시행합니다.
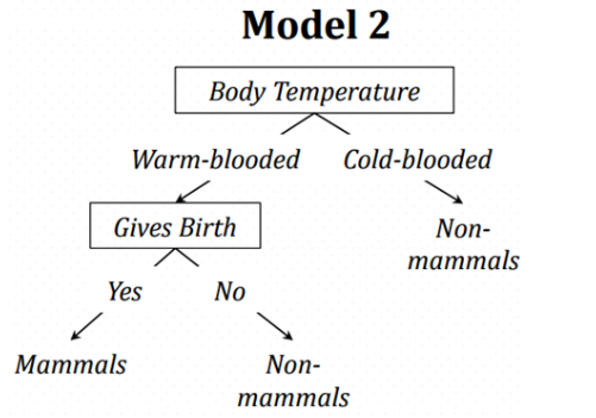
가지치기를 한 후의 Model :
가지치기를 했을 경우의 모델 정확도 그래프 :
참고 영상 :
출처 : 쉽게 읽는 머신 러닝 - 라온피플