지난 포스트에는 머신러닝 중 한가지인 Decision Tree에 대해서 알아보았습니다.
[쉽게읽는 머신러닝-라온피플] 3. Decision Tree
오늘은 또다른 머신러닝의 모델 중 하나인 Naive Bayes에 대해 알아보는 시간을 가지겠습니다!
그럼, 출발할까요?!
‘Bayes Theorem’에 기반한 분류기(Classifier)입니다. ‘Naive’가 붙는 이유는 그것의 가정이 맞을 수도 틀릴 수도 있기 때문입니다.
간단히 말해서, Naive Bayes Classifier는 한 클래스의 특징의 존재가 그 클래스의 다른 특징의 존재와 연관이 안되어있다고 가정합니다. 예를 들면, 만약 빨간색이고, 둥글며, 4인치 둘레인 과일을 사과라고 해보죠. 이 특징들은 서로 어느정도 종속적임에도 불구하고 Naive Bayes Classifier는 이 모든 특징들이 일어날 확률을 전부 독립이라고 가정합니다.
이 때문에 ‘Simple Bayes’나 ‘Idiot Bayes’ (단순, 멍청…) 라고도 불립니다. 특징이 많을때 ‘단순화’ 시켜 빠르게 판단을 내릴 때 주로 사용됩니다.
(예, 문서 분류, 질병 진단, 스팸 메일 분류 등)
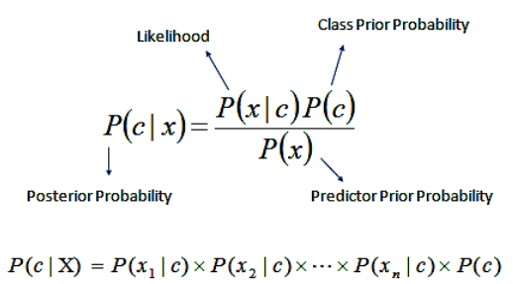
중요한 부분은 특정 개체x를 규정짓는 특징들(x1, … ,xn)이 서로 독립적이라면, P(x|c)는 위 식처럼 각각의 특징들이 발생할 확률의 곱으로 쉽게 표현할 수 있습니다.
‘Drew’라는 이름을 갖는 사람이 많이 있는 경우를 생각해보죠. 아래 그림처럼 ‘Drew’는 여자일수도, 남자일수도 있습니다. ‘Drew’라는 이름을 가진 남자 그룹을 c1, 여자그룹을 c2라고 하죠.

그럼 ‘Drew’라는 사람이 c1에 속할 확률은 어떻게 될까요?
바로 아래 식처럼 됩니다.
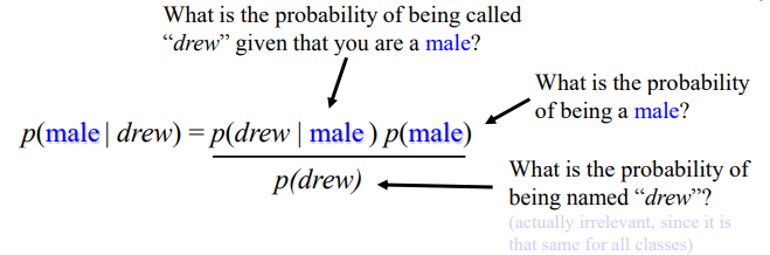
(P(male|drew) : ‘Drew’의 이름을 가진 사람이 남자일 확률
P(drew|male) : 남자가 ‘Drew’의 이름을 가질 확률
P(male) : 남자일 확률
P(drew) : 이름이 ‘Drew’일 확률)
여기서, 한 경잘서에 있는 경찰관의 이름이 아래 표로 주어졌을 때, ‘Drew’라는 이름의 사람이 남자인지 여자인지 판별해봅시다!
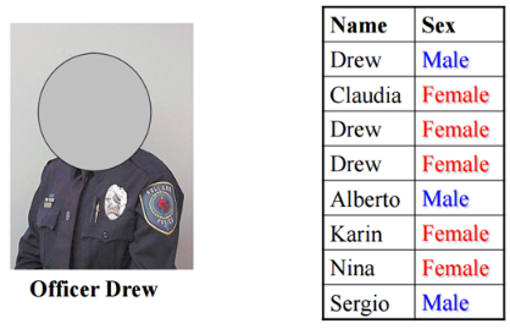
이 문제를 풀려면, P(male|drew)와 P(female|drew)을 구해 큰 쪽을 선택합니다.
Bayes 식에 따라 계산을 하면,

따라서, ‘Drew’라는 이름을 쓰는 경찰관은 여성일 확률이 높다는 것을 알 수 있습니다!