Author : Duck Hyeun, Ryu
지난 포스트에는 머신러닝 모델중 강력하다고 알려진 Support Vector Machine에 대해서 알아보았습니다.
[쉽게읽는 머신러닝-라온피플] 5. Support Vector Machine
오늘은 인공 신경망을 사용하는 비지도학습 머신러닝인 Autoencoder에 대해서 간략히 알아보는 시간을 가지겠습니다.!
출바아아ㅏㅏㅏ알ㄹㄹㄹㄹ!
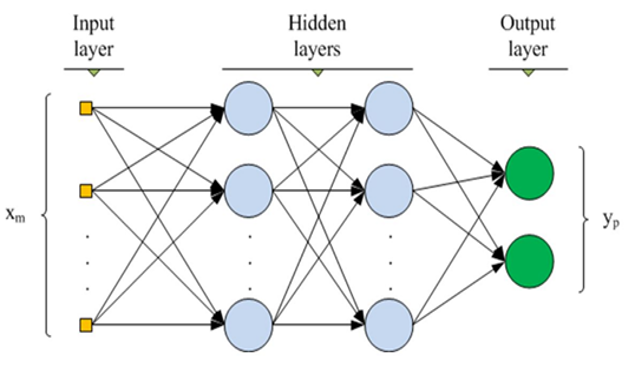
Hidden layer가 여러게 있는 Perceptron 입니다. (1. 머신러닝 Framework에서 Perceptron의 개념을 확인할 수 있습니다.)
이는 지도학습 모델입니다. 실제 출력값과 기대값의 차를 확인하여 역전파(Back Propagation)방법을 이용하여 파라미터 값을 조금씩 변화시키는 방식을 사용합니다.
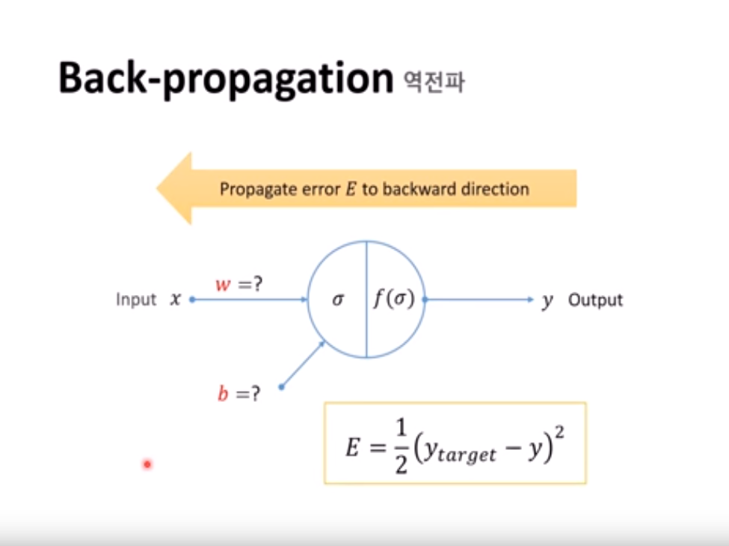
(x : input, y : output, w : 가중치, b : bias, E : error, ytarget : 기대값, σ = wx + b, f(σ) : 활성함수)
무작위로 w와 b를 조절하는 것은 시간이 너무 많이 걸립니다. 그래서 Error를 이용해서 w와 b를 결정합니다.
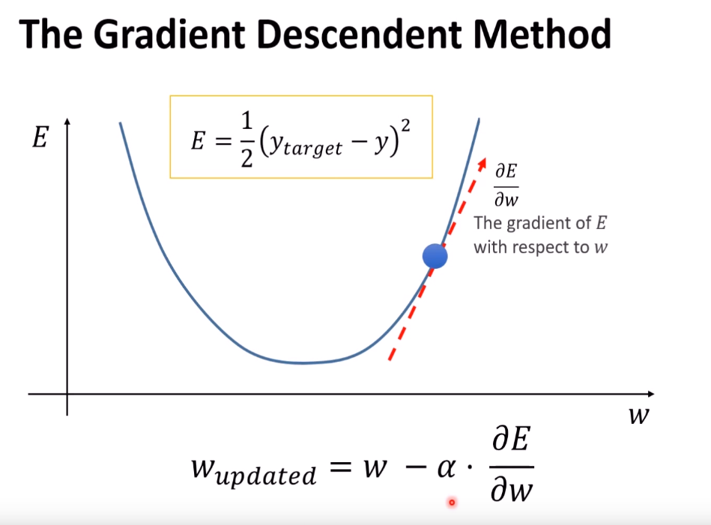
(wupdate : 새로 바꿀 w, α : Learning late)
w의 경우 만약 b를 결정하고 싶으면 b에 대한 E의 변화량을 계산합니다.
참고영상 :
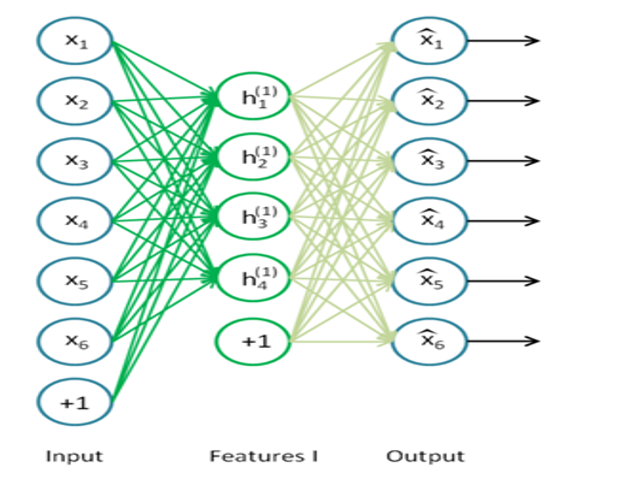
학습의 목표는 출력값을 입력값에 근사시키는 것입니다. Hidden layer의 뉴런 개수는 입력값보다 일번적으로 작습니다. 이렇게 차원을 줄이는 과정에서 유의미한 특성을 뽑아냅니다.
MLP와 다르게 지도학습이 아니라 비지도학습(자율학습)입니다. 입력에서 Hidden layer로 넘어가는 과정을 Encoding이라 하고, Hidden layer에서 출력값으로 넘어가는 것을 Decoding이라고 합니다.
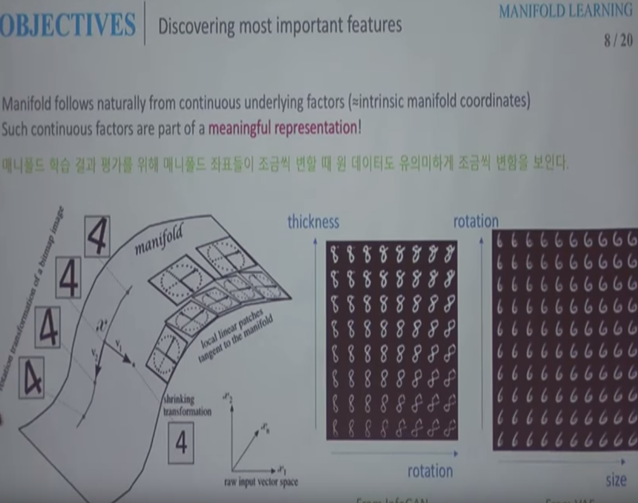
예를 들어 8과 관련된 여러가지 이미지를 Input으로 넣었다죠. 이때 그 이미지의 차원은 256 * 256 * 3이라 가정합니다.
8에 관련된 이미지는 균일하게 흩어져 있는 것이 아닌 어느 부분에 모여 있을 것이고, 그에 해당되는 종속공간(부분공간, Subspace)을 뽑아낼 수 있을 것입니다. 이것을 Manifold라고 합니다.
위 그림은 Autoencoder에 2D로 압축하라고 명령을 내린다면 자동적으로 Rotation과 Thickness라는 Feature 두개를 찾아내는 것을 보여주고 있습니다.
차원을 의미있게 줄이는 것을 뜻합니다.
Autoencoder에 있는 Hidden layer의 뉴런 개수가 입력보다 크거나 같으면 Identity함수가 구현될 확률이 높습니다. 그렇게 되면 유용한 특성(Feature)을 얻어낼 수 없으므로 이를 막을 제한 조건으로 Hidden layer의 뉴런 개수를 낮춰줍니다. 주요한 차원 축소를 하는 기법으로 Principle Compenet Analysis(PCA)도 있는데 PCA는 선형적인 한계가 있습니다.
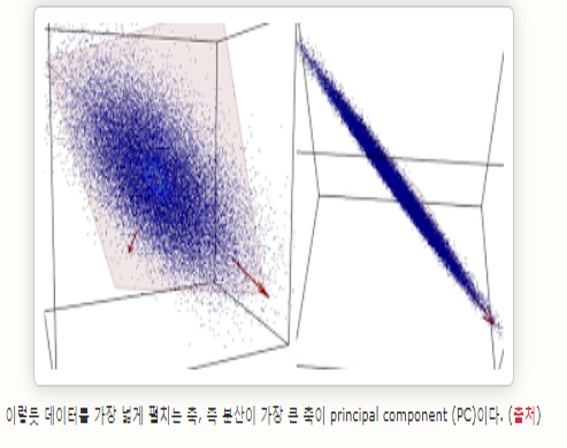
만약 3차원 공간의 데이터들이 2차원 평면상에 가지런히 놓여있으면 PCA가 잘 작동되겠지만 2차원 평면이 굽어있다는 PCA는 한계를 보일것 입니다.
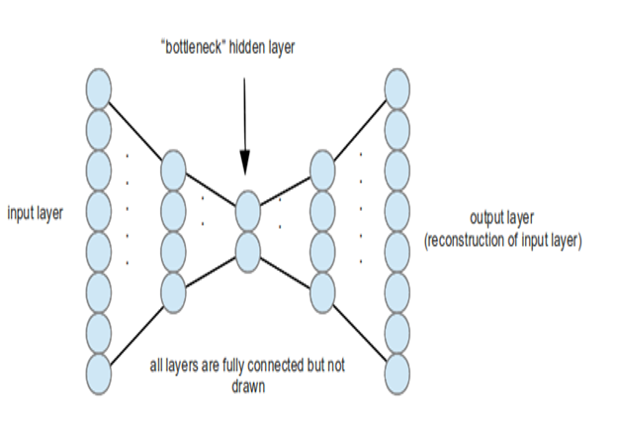
Hidden layer를 여러개 쌓아서 구현하는 AE입니다. 가장 압축된 Feature가 얻어지는 layer를 Bottleneck hidden layer라고 합니다. Stacked AE방식은 Greedy layer-Wise training 방법을 사용합니다.
Auto encoder도 MLP와 마찬가지로 역전파를 통해서 학습을 하는데 활성함수의 미분값이 0 근처로 가면 학습이 어려워지거나 느려지는 문제가 발생합니다. 이 문제를 피할 수 있는 것이 바로 Greedy layer-Wise training 입니다.
Greedy layer-Wise training 은 첫번째로 hidden layer에 대한 학습을 진행합니다. 두 번째 hidden layer를 학습시킬 때는 학습 시킨 첫번째 hidden layer의 파라미터는 고정시킵니다. 두 번째 hidden layer의 입력은 첫번째 hidden layer의 입력을 사용하므로 결과적으로 기본 AE가 됩니다. 그 다음 layer들도 마찬가지로 그 전 뉴런들의 파라미터들을 고정시키고 학습 시킵니다.
신경망을 학습시키려면 label이 달린 학습데이터가 필요한데 그런 데이터는 많이 없습니다. 이 경우 label이 없는 데이터를 Greedy layer-Wise training 으로 사전학습 시킬 수 있습니다. 이것을 Unsupervised Pre-training이라고 합니다.
하지만 이 방법은 2010년 이후 Rectifier Linear unit(ReLU)이라는 활성함수가 발표되고 dropout, maxout, data augmentation , batch normalization방법이 발표되면서 사용하지 않게 되었습니다.
잡음을 제거(Denoising)할 수 있는 AE입니다.

먼저 잡음이 없는 영상 x에 잡음을 가하여
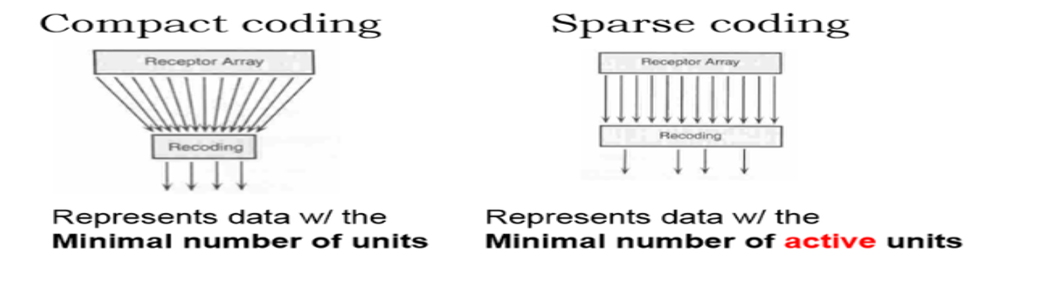
Sparse coding은 기본적으로 아래와 같은 식으로 표현이 가능한데 식의 왼쪽은 AE에도 있는 Error부분을 나타내고 오른쪽은 Sparsity를 강제하기 위한 항목입니다.
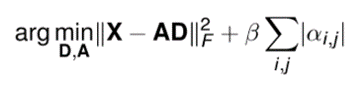

Sparse coding을 이용하여 Denoising을 한 예입니다.

이 예는 Inpainting(영상 복원 기술) sparse coding을 참고한 경우입니다.
Sparse coding도 AE와 마찬가지로 데이터를 Compact하게 만드는 것이 목적입니다. Sparse coding의 기저함수는 원 데이터 보다 큽니다. 벡터 s에서 대부분의 계수를 0으로 만들면 결과를 Compact하게 만들 수 있습니다.
(마찬가지로 좀더 자세한 것은 후에 Hands-on Machine Learning책을 정리할때 다루겠습니다.)